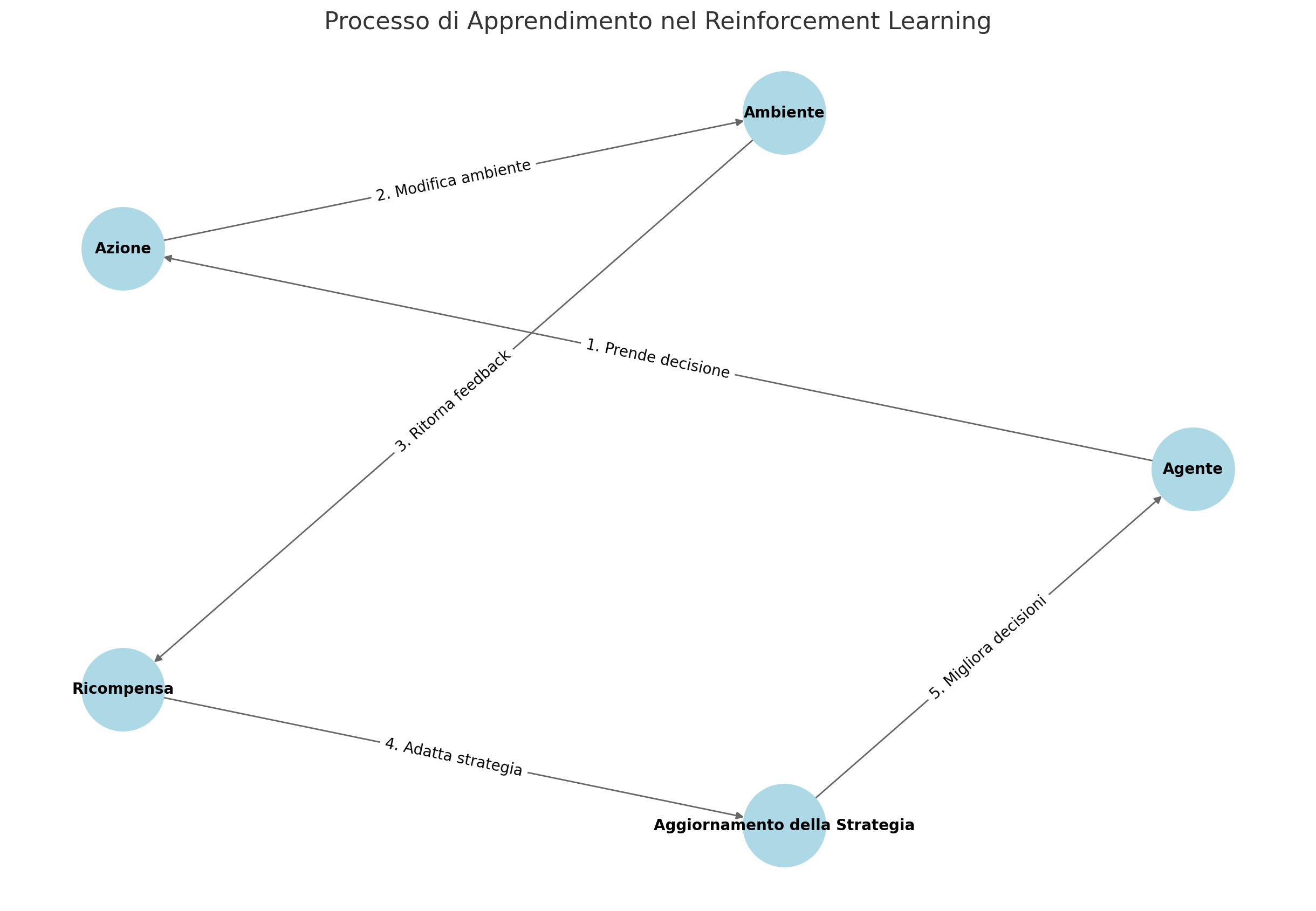

Il reinforcement learning è una tecnica che si distingue per la sua capacità di apprendere attraverso l’interazione diretta con l’ambiente, un aspetto che lo rende diverso da altri tipi di apprendimento automatico come il supervised learning e l’unsupervised learning.
Nel trading, il backtesting è una tecnica fondamentale per valutare la validità di una strategia prima di implementarla sul mercato reale. Nei sistemi tradizionali, si suddivide lo storico dei dati in due parti: una per l’addestramento e una per il test. Questo approccio, pur valido, presenta dei limiti, poiché le regole che governano il sistema rimangono statiche. Il reinforcement learning offre una soluzione a questo problema, permettendo all’agente di continuare ad apprendere anche dopo la fase di addestramento iniziale. L’agente riceve continuamente aggiornamenti dall’ambiente di lavoro e, basandosi su questi, prende decisioni che influenzano l’ambiente stesso. Questo ciclo continuo permette all’agente di adattarsi non solo alle ricompense immediate, ma anche alle fluttuazioni a lungo termine del mercato. Ad esempio, in un mercato in calo, un agente può reagire modificando la sua strategia di vendita per ridurre le perdite, mentre in un mercato in rialzo può cavalcare l’onda dei profitti.
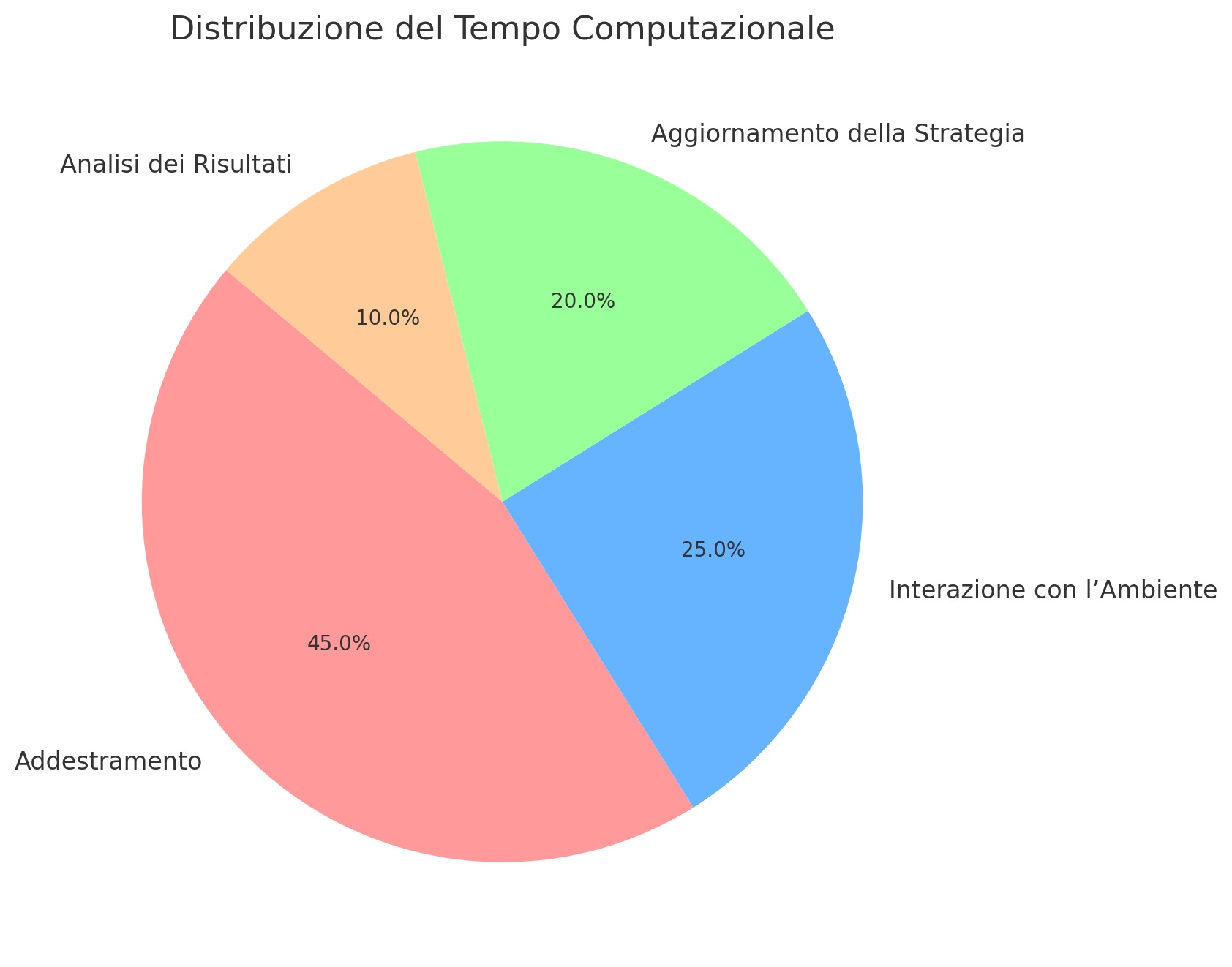
Nonostante i numerosi vantaggi, sono presenti anche delle problematiche. Prima di tutto, richiede una grande potenza di elaborazione, specialmente durante la fase di addestramento. Inoltre, può soffrire di instabilità se l’ambiente non tiene conto di tutti i parametri rilevanti. Questo può portare a decisioni subottimali o persino errate. Un altro punto critico è la gestione di eventi imprevisti o di fattori esogeni, come una crisi finanziaria improvvisa. In questi casi, l’agente potrebbe non essere in grado di adattarsi immediatamente, poiché il suo modello è basato su esperienze passate che potrebbero non includere situazioni simili. Tuttavia, con il tempo e l’aumento della potenza di calcolo disponibile, è probabile che questi sistemi diventeranno sempre più robusti.